Captcha har utviklet seg fra å identifisere lemlestede brev til internett-brukere uforvarende trening Googles AI. Nå, endelig, du trenger ikke å gjøre noe
@alexhern
Mon 13 Mar 2017 15.39 GMT
Sist endret på Mon 13 Mar 2017 17.02 GMT
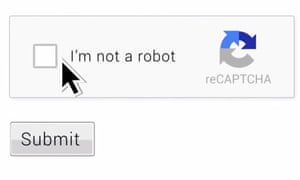
ReCaptcha … Googles ny versjon av “du er en robot” – test ved ganske enkelt å spørre brukerne.
Foto: Google
Opplevelsen av skjeling på forvrengt tekst, gåtefullt over små bilder, eller til og med å klikke på avmerkingsboksen for å bevise at du ikke er en robot kan snart være over, hvis en ny Google tjenesten tar av.
Selskapet har avslørt den siste utviklingen av Captcha (kort, liksom, for Fullstendig Automatisert Offentlig Turing test å fortelle Datamaskiner og Mennesker Apart), som har som mål å gjøre unna med noen avbrudd i det hele tatt: den nye, “usynlig reCaptcha” har som mål å fortelle om et gitt besøkende er en robot eller ikke rent ved å analysere sine surfing oppførsel. Sperring av kort vent mens systemet gjør jobben sin, en typisk menneskelig besøkende skal slippe å gjøre noe annet for å bevise at de ikke er en robot.
Det er en lang vei fra den første Captchas, som ble innført for å stoppe automatiske programmer du registrerer deg for tjenester som e-postadresser og sosiale medier kontoer. Ideen er enkel: velg en oppgave, at et menneske kan gjøre enkelt, og en maskin som finner svært vanskelig, og krever at oppgaven være ferdig før prosessen kan bli videreført.
Den første captchas ofte lettelse opp på forvirrende tekst: et par bokstaver og tall, uklar, forvrengt, eller på annen måte gjengis vanskelig å analysere med konvensjonelle tegngjenkjenning programvare. Selv da de fortsatt var forbigått ganske ofte. Begrenset antall tegn som er tilgjengelig i det latinske alfabetet ment at programvaren kan raskt forbedre til en akseptabel grad av nøyaktighet, mens obfuscating bokstavene ytterligere kan føre til virkelige mennesker – spesielt de med dårlig syn – å bli låst ut.
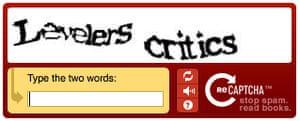
Den første versjonen av reCaptcha. Foto: Google
Og det var bare når systemet ikke var satt opp dårlig på andre måter. For eksempel, en billett tout i midten av 00s, møtt med en Captcha på Ticketmaster, oppdaget at hele systemet var pre-generert: billettering nettstedet hadde bare ligger rundt 30 000 captchas i sin database. De tout team enkelt lastes ned hver Captcha image de kunne, da oppholdt opp hele natten manuelt å løse dem. Fra da av, bot kunne kjøpe billetter automatisk uten at det er et problem.
Men den første store gjennombrudd i Captchas å treffe nettet hadde ingenting å gjøre med å gjøre det vanskeligere for roboter til å passere dem. I stedet ble det en innsikt som alle forsøk på mennesker var å sette inn stirrer på squiggly tekst kan være langt bedre anvendt.
Kalt reCaptcha, ideen kom fra Luis von Ahn i 2008, en professor ved Carnegie Mellon University som har siden co-grunnlagt språklæring oppstart Duolingo. Von Ahn innså at hvis mennesker var å gjøre noe som datamaskiner funnet vanskelig å lese forvrengt tekst – de bør i det minste være å lese tekst som er nyttig.
ReCaptcha erstattet den auto-genererte tekst i forrige Captchas med ord hentet fra skannet tekst som for eksempel aviser, bøker og magasiner: tekst som trengs for å bli omgjort til-maskin-lesbar type. Det er fortsatt forvrengte bilder, for å holde datamaskiner ut, men den virkelige ord skrevet i ble matet tilbake til database for å forbedre den opprinnelige informasjonen.
Google-video som illustrerer det nye systemet
Det introdusert et annet problem, skjønt: hvis en datamaskin ikke kan lese ordet presentert, hvordan fungerer systemet vet om brukeren har det rett eller galt? Von Ahn ‘ s løsning, var til stede par ord, en som allerede er løst, og et ukjent ord. Hvis løsningen for de første kampene som gitt tidligere, så brukeren er trolig et menneske – og så den andre svar blir også lagt til databasen, og deretter presentert for en ny bruker.
Ideen var overbevisende, spesielt til en internett-titan: i September 2009, Google kjøpte reCaptcha. Kjøpet gjorde forstand. Selskapet hadde ikke bare et stort antall lage konto forespørsler, takk til spammere prøver å lage gmail-kontoer i hopetall, det hadde også en betydelig korpus av tekst for å digitalisere, som på grunn av sine kontroversielle planlegger å skanne i millioner av bøker og aviser. Slike insentiver betydde også Google kan gjøre reCaptcha gratis for andre selskaper å bruke, med serveren kostnader blir tjent inn igjen av verdifulle data.
Men selv om reCaptcha laget som beviser at du er en menneskelig nyttig, det kunne ikke slå fremdriften av automatisk tekstgjenkjenning. Så tidlig som i 2008, Captcha-konseptet var allerede begynt å falle bak. Ikke bare var roboter bli bedre til å lese selv forvrengt tekst, men spammere var i ferd med å bruke reCaptcha konsept mot det: hvis mennesker kan gjøre jobben bedre enn roboter, hvorfor ikke få dem til å gjøre arbeidet? Ved å tilby noe gratis (dette er internett, er det vanligvis porno), en spammer kan ofte overbevise folk til å løse andre siden er Captchas for dem, ved å bare kopiere bildet over.
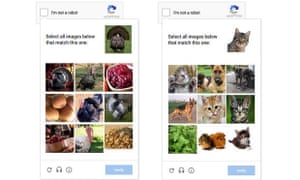
Bilde matching er raskere og enklere for mennesker, men er fortsatt vanskelig for roboter. Foto: Google
Captchas har utviklet seg i respons, med Google å innføre stadig mer subtile teknologiske triks for å prøve og fortelle om en bruker er eller ikke er et menneske. Som kulminerte i 2014, når det innført “Ingen Captcha reCaptcha”. Formen ser ut som en enkel boks: krysse den for å bekrefte at du ikke er en robot.
I motsetning til tekst-basert Captchas, mekanismer som Google forteller om det å håndtere en robot ble bevisst skjult. Selskapet sa det ansatt “avansert risikoanalyse” – programvare, som overvåker ting som hvordan brukeren typer, hvor de flytter musen, hvor de klikker på og hvor lang tid det tar dem til å skanne en side, alle med mål om å arbeide ut som atferd er et menneske-som og som er for robot.
Det er sannsynlig hvordan den nye Usynlig reCaptcha fungerer, selv om selskapet er enda mer stille med hensyn til det. I svar på en forespørsel om utdyping, Google bare knyttet til en salgsfremmende video.
Men Ingen Captcha reCaptcha ikke bety døden av nyttig Captchas. I stedet har de utviklet seg også, og gå utover tekst for å hjelpe Google med andre big data prosjekter.
Hvis Google bestemmer du ikke menneske med sin rare voodoo, det vil nå vise deg en samling av bilder og ber deg om å uforvarende trene sine maskin-læring systemer på ulike måter. Noen brukere kan bli vist et rutenett full av dyr bilder og bli bedt om å velge hver katt (nyttig trening for Google Bilder’ evne til å søke gjennom bilder for søkeordene du gi), mens andre kan være vist et bilde tatt fra en Street View bilen og bedt om å skrive inn døren antall hus (nyttig for å forbedre nøyaktigheten av selskapets kart) eller velg alle deler av bildet som inneholder veiskilt (nyttig for opplæring selskapets selvkjørende biler). Atter andre kan være vist et bilde av et militært helikopter og bedt om å velge alle rutene som inneholder et helikopter (nyttig trening for … vel, sannsynligvis for bilde anerkjennelse, men kanskje for Google plan om å ta over verden med AI).
Til slutt, skjønt, Google ‘ s plan for å fjerne byrden av reCaptchas helt betyr at det vil bli mindre og mindre av denne beskjed fra sluttbrukere. Men gitt selskapets skala, selv folk som ikke klarer den usynlige reCaptcha kan godt gi nok ekstra data til å gi Google ‘ s AI planer ennå mer av et løft mot konkurranse. Hvem vet, kanskje den Usynlige Captcha er også trening en AI hvordan å oppføre seg som et menneske online?