Captcha har utvecklats från att identifiera sargade brev till webb-användare omedvetet utbildning Googles AI. Nu, äntligen, kommer du inte att göra något
@alexhern
Mån 13 Mar 2017 15.39 GMT
Senast ändrad Mån 13 Mar 2017 17.02 GMT
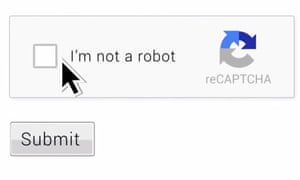
ReCaptcha … Googles återuppfunnit “är du en robot” test genom att helt enkelt be användare.
Foto: Google
Erfarenhet av skelning på förvrängd text, förbryllande över små bilder, eller helt enkelt att klicka i en kryssruta för att bevisa att du inte är en robot kan snart vara över, om en ny tjänst från Google tar bort.
Bolaget har visat den senaste utvecklingen av Captcha (kort, typ, för Helt Automated Public Turing test to tell Computers and Humans Apart), som syftar till att göra sig av med några avbrott alls: den nya, “osynliga reCaptcha” syftar till att berätta om en given besökare är en robot eller inte enbart genom att analysera deras surfar beteende. Spärra ett kort och vänta medan systemet gör sitt jobb, en typisk människa ska inte behöva göra något annat för att bevisa att de inte är en robot.
Det är en lång väg från den första Captchas, som infördes för att stoppa automatiska program registrerar dig för tjänster som e-post adresser och sociala medier. Idén är enkel: välj en uppgift om att en människa kan göra enkelt, och en maskin som finner mycket svårt, och kräver att uppgift vara klar innan processen kan fortsätta.
Den första captchas ofta förlitat sig på förvrängd text: några bokstäver och siffror, suddig, förvanskas eller på annat sätt återges svårt att tolka med konventionell programvara för teckenigenkänning. Även då de fortfarande var förbi ganska ofta. Det begränsade antalet tecken som är tillgängliga i det latinska alfabetet innebar att programvaran kan snabbt bli till en bra nivå av noggrannhet, samtidigt som fördunklar de bokstäver som ytterligare skulle kunna leda till verkliga människor – särskilt de med dålig syn – att vara låst.
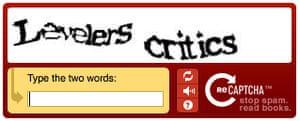
Den första versionen av reCaptcha. Foto: Google
Och det var endast när systemet var inte ställa upp dåligt på andra sätt. Till exempel, en biljett tout i mitten av 00-talet, inför en Captcha på Ticketmaster, upptäckte att hela systemet var förgenererade: biljettsystem webbplats hade bara lastas cirka 30 000 captchas i sin databas. De tout team helt enkelt laddas ned varje Captcha-bild de kunde, sedan stannade uppe hela natten manuellt lösa dem. Från och med då, bot kunde köpa biljetter automatiskt utan problem.
Men den första stora genombrott i Captchas för att slå på webben hade ingenting att göra med vilket gör det svårare för robotar att passera dem. Istället var det en insikt om att alla de ansträngningar som människor sätter i stirrade på snirkliga texten skulle vara mycket bättre tillämpas.
Kallas reCaptcha, idén kom från Luis von Ahn under 2008, en professor vid Carnegie Mellon University, som har sedan dess co-grundades av språkinlärning start Duolingo. Von Ahn insåg att om människor var att göra något som datorer hittades svårt – att läsa förvrängd text – att de åtminstone borde vara att läsa text som är användbar.
ReCaptcha ersatt den autogenererade text i föregående Captchas med ord hämtade från skannade texten såsom dagstidningar, böcker och tidskrifter: text som behövs för att förvandlas till en dator typ. Det är fortfarande förvrängda bilder, för att hålla datorer ut, men den verkliga ord skrivs i matades tillbaka till databasen för att förbättra den ursprungliga informationen.
Googles video som illustrerar det nya systemet
Det infördes en andra problem: om datorn inte kan läsa ordet som presenteras, hur vet systemet om användaren fick det rätt eller fel? Von Ahn: s lösning var att presentera par ord, en redan löst och ett okänt ord. Om lösningen för det första matcher som angetts tidigare, då användaren är förmodligen en människa – och så det andra svaret får också läggas in i databasen, och därefter presenteras för en ny användare.
Tanken var övertygande, särskilt till en internet-titan: i September 2009, Google köpte reCaptcha. Köp förnuft. Bolaget hade inte bara ett stort nummer av att skapa konto önskemål, tack vare spammare som försöker att skapa ett gmail-konton i en grupp, det hade också en betydande samling av text för att digitalisera, resultatet av sitt kontroversiella planerar att skanna in miljontals böcker och tidningar. Dessa incitament innebar också att Google skulle kunna göra reCaptcha gratis för andra företag att använda, med servern kostnader som tjänas in genom att värdefulla data.
Men även om reCaptcha som gjorts som visar att du är en människa användbart, att det inte kunde slå utvecklingen av automatisk textigenkänning. Så tidigt som 2008, Captcha-konceptet var redan börjat halka efter. Inte bara var robotar blir bättre och bättre på att läsa även förvrängd text, men spammare börjar använda reCaptcha koncept mot det: om vi människor kan göra arbetet bättre än robotar, varför inte få dem att göra jobbet? Genom att erbjuda upp något gratis (detta är internet, det är oftast porr), en spammare kan ofta övertyga människor att lösa andra webbplatsens Captchas för dem, genom att bara kopiera bilden över.
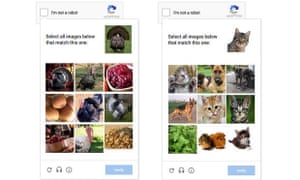
Bild matchning är snabbare och enklare för människor, men det är fortfarande svårt för robotar. Foto: Google
Captchas har utvecklats, med Google att införa alltmer subtila tekniska knep för att prova och avgöra om en användare är eller inte är en människa. Som kulminerade i och med 2014, när man införde “Ingen Captcha reCaptcha”. Formen ser ut som en enkel låda: kryssa i den för att bekräfta att du inte är en robot.
Till skillnad från text-baserade Captchas, de mekanismer som Google berättar om det har att göra med en robot var medvetet skyms. Bolaget sade att det som är anställd “avancerad riskanalys”, programvara, som övervakar saker som hur användaren typer, där de flyttar musen, där de klickar på och hur lång tid det tar för dem att skanna en sida, alla med målet att arbeta ut vilka beteenden som är mänskliga-liknande och som är för robot.
Det är sannolikt hur den nya Osynliga återge verk, även om företaget ännu mer tyst när det gäller detta. I svar på en begäran om utarbetande, Google endast är kopplad till en pr-video.
Men Ingen Captcha reCaptcha inte betyder död användbara Captchas. Istället, de har utvecklats för, att röra sig bortom texten för att hjälpa Google: s andra stora data-projekt.
Om Google bestämmer sig för att du inte är mänsklig med sina konstiga voodoo, det kommer nu att visa dig en samling av bilder och ber dig att omedvetet träna sin maskin-system för lärande på olika sätt. Vissa användare kan vara visas ett rutnät som är full av djur bilder och bli frågad att välja varje katt (användbar utbildning för Google Bilder förmåga att söka igenom bilder för sökord som du tillhandahåller), andra kan vara visas en bild tagen från en Street View-bil och ombedd att skriva in nummer av hus (användbart för att förbättra noggrannheten av företagets kartor) eller väljer varje del av bilden som innehåller vägskyltar (användbart för utbildning av bolagets självstyrande bilar). Ytterligare andra kan vara visas en bild av en militär helikopter och frågade om du vill markera alla rutor som innehåller en helikopter (användbar utbildning för … tja, förmodligen för bildigenkänning, men kanske för Googles plan att ta över världen med AI).
Men slutligen, Googles plan att ta bort bördan av reCaptchas helt och hållet innebär att det kommer att bli mindre och mindre av denna information från användarna. Men med tanke på bolagets skala, även de människor som misslyckas med det osynliga reCaptcha kan väl ge tillräckligt med extra data för att ge Googles AI planer ännu mer av ett uppsving mot konkurrensen. Vem vet, kanske den Osynliga Captcha är också en utbildning AI hur man ska agera som en människa på nätet?