
Den berömde fysikern Richard Feynman sa en gång: “Vad jag inte kan skapa, jag förstår inte. Lära sig att lösa varje problem som redan är lösta”. Tillämpningsområdet för neurovetenskap, som i allt högre grad fart, tog Feynman ord till hjärtat. För forskare, teoretiker nyckeln till att förstå hur den intelligens som kommer att bli hans rekreation insidan av din dator. Neuron till neuron, som de försöker att återupprätta den neurala processer som ger upphov till tankar, minnen och känslor. Att ha en digital hjärnan, forskare möjlighet att testa våra nuvarande teorier om kunskap eller för att utforska parametrar som leder till störningar av hjärnans funktion. Som föreslagits av filosofen Nick Bostrom vid Universitetet i Oxford, en imitation av det mänskliga medvetandet är en av de mest lovande (och svårt) sätt att återskapa — och överträffa — människans uppfinningsrikedom.
Det finns bara ett problem: våra datorer inte kan hantera parallella arten i våra hjärnor. I polutorachasovom kroppen vriden, mer än 100 miljarder nervceller och biljoner synapser.
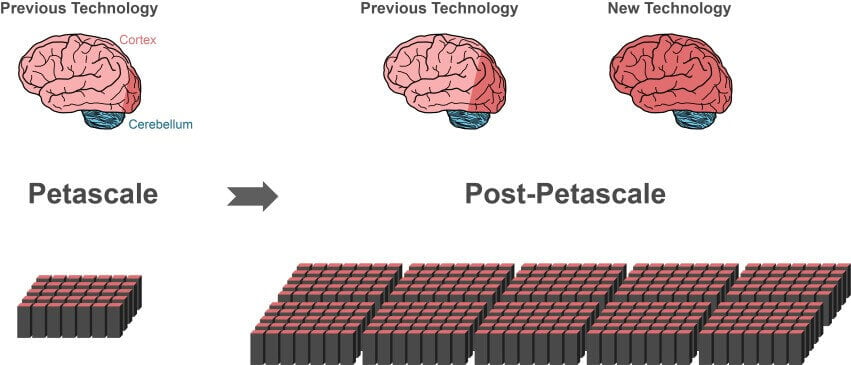
Även de mest kraftfulla superdatorer i dag är bakom dessa skalor, som K dator av Advanced Institute for computational science i Kobe, Japan, kan processen inte mer än 10% av nervceller och deras synapser i hjärnbarken.
En del av slack i samband med programvaran. Blir snabbare dator utrustning, mer algoritmer bli grunden för en fullständig simulering av hjärnan.
Denna månad en internationell grupp av forskare har helt reviderad struktur populära algoritm för simulering genom att utveckla en kraftfull teknik som radikalt minskar beräkningstiden och minnesanvändning. Den nya algoritmen är kompatibel med olika typer av it-utrustning, från bärbara datorer till superdator. När framtiden super-datorer levereras på scenen — och de är 10-100 gånger mer kraftfull än den nuvarande — algoritmen är omedelbart tillämpas på dessa monster.
“Tack vare ny teknik kan vi använda det ökande drag i moderna mikroprocessorer är mycket bättre än förut”, säger studiens författare Jacob Jordanien, Research center Julia i Tyskland. Arbetet publicerades i Gränser i Neuroinformatics är.
“Detta är ett avgörande steg mot skapandet av en teknik för att uppnå simulering av nätverk i hela hjärnan,” skriver författarna.
Problemet med skala
Moderna superdatorer består av hundratusentals underdomäner noder. Varje nod innehåller flera behandlingshem, som kan stödja en handfull av virtuella nervceller och deras anslutningar.
Det största problemet i simuleringen av hjärnan är hur man på ett effektivt sätt representerar miljontals nervceller och deras anslutningar i dessa centra för att spara på tid och kraft.
En av de mest populära simulering algoritmer — Minne-Användning Modell. Innan forskare simulera förändringar i deras neurala nätverk, de måste först skapa alla dessa nervceller och deras anslutningar i den virtuella hjärnan med hjälp av algoritmen. Men här är haken: för varje par av nervceller, den modell som lagrar all information om anslutningar vid varje nod, som är den mottagande nervcellen — postsynaptiska nervcellen. Med andra ord, den presynaptiska neuron, som skickar elektriska impulser, skrek i tomrummet; algoritmen måste avgöra om ett visst meddelande, genom att enbart se på mottagarnervcellen och data som lagras i noden.
Det kan tyckas märkligt, men den här modellen gör att alla noder att bygga sin del av arbetet i neurala nätverk parallellt. Detta dramatiskt minskar ner tiden, vilket delvis förklarar populariteten av denna algoritm.
Men som ni kanske har gissat, det finns allvarliga problem med skalning. Avsändaren nod skickar ett meddelande till alla mottagande av neurala noder. Detta innebär att varje mottagande noden måste sortera meddelanden i nätverket — även de som är avsedd för enheter som är belägna i andra noder.
Detta innebär att en stor del av budskapet är kass på varje nod, speciellt eftersom det inte finns någon neuron till vilken det är riktat. Tänk att posten skickar alla anställda i landet för att utföra ett önskat meddelande. Galet ineffektivt, men det fungerar enligt principen modell av minne.
Problemet blir allvarligare med tillväxten av storleken av den simulerade neurala nätverk. Varje nod måste avsätta utrymme för minnet “address book” som listar alla neurala invånare och deras relationer. I omfattningen av miljarder neuroner “adressbok” blir ett stort träsk av minne.
Storleken eller källa
Forskare har knäckt problemet genom att lägga till algoritmen… index.
Här är hur det fungerar. Den mottagande noder innehåller två bitar av information. Den första är en databas som lagrar information om alla nervceller-sändare som ansluts till knutpunkter. Eftersom synapser finns i flera storlekar och typer, som skiljer sig i minne, den databas som också sorterar dina uppgifter beroende på vilka typer av synapser bildas av nervceller i nod.
Denna inställning är mycket annorlunda från tidigare modeller i vilka föreningar som var sorterad från inkommande källa av nervceller, och den typ av synapsen. På grund av detta, noden kommer inte längre att stödja “adressbok”.
“Storleken på den datastruktur som därmed upphör att vara beroende av det totala antalet neuroner i nätet”, förklarar författarna.
Det andra blocket lagrar data om den faktiska kopplingar mellan den mottagande nod och avsändaren. Som den första enheten, det ordnar data i enlighet med den typ av synapsen. I varje typ av synaps är separerade från datakällan (skicka neuron).
Alltså, denna algoritm är specifika till sin föregångare: i stället för att lagra all information om anslutning i varje nod, den mottagande noder bara lagra de data som motsvarar virtuella nervceller i dem.
Forskarna gav också varje skicka neuron till målet adressbok. Under överföring data delas upp i bitar, varje fragment som innehåller kod, postnummer, sänder den till lämplig mottagande noder.
Snabb och smart
Ändring fungerade.
Under testning, den nya algoritmen visade sig mycket bättre än sina föregångare, när det gäller skalbarhet och hastighet. På superdator JUQUEEN i Tyskland, den algoritm som arbetat med 55% snabbare än tidigare modeller på slumpmässiga neurala nätverk, främst tack vare dess enkla system för överföring av data.
I ett nätverk storleken av en halv miljarder nervceller, till exempel simulering av en sekund av biologiska händelser som tog ca fem minuter av arbetstiden på JUQUEEN nya algoritmen. Modell-föregångare tog in sex gånger mer tid.
Som väntat, flera skalbarhet tester visade att den nya algoritmen är mycket mer effektiv i hanteringen av stora nätverk, eftersom det minskar handläggningstiden för tiotusentals överför data tre gånger.
“Fokus är nu på att snabba upp simuleringen i förekomsten av olika former av nätverk plasticitet”, avslutar författarna. Med detta i åtanke, slutligen, digital mänskliga hjärnan kan vara inom räckhåll.
Den nya algoritmen har fört oss till en komplett simulering av hjärnan
Ilya Hel