Det bedste gæt er, at mennesker i øjeblikket taler om 6,900 forskellige sprog. Mere end halvdelen af verdens befolkning kommunikerer ved hjælp af blot en håndfuld af dem—Kinesisk, engelsk, Hindi, spansk og russisk. Ja, 95 procent af mennesker, der kommunikerer ved hjælp af kun 100 sprog.
Den anden argots er meget mindre udbredt. Ja, lingvister, anslår, at omkring en tredjedel af verdens sprog tales af færre end 1.000 mennesker og er i fare for at dø ud i de næste 100 år eller så. Med dem vil gå den unikke kulturarv, som de repræsenterer—historier, sætninger, vittigheder, naturlægemidler, og endda unikke følelser.
Det er let at tro, at machine learning kan hjælpe. Problemet er, at maskinoversættelse er afhængig af enorme kommenteret datasæt for at drive sin handel. Disse datasæt, der består af meget store korpora af bøger, artikler og hjemmesider, der har været manuelt oversat til andre sprog. Dette fungerer som en Rosetta-Sten for machine-learning algoritmer, og jo større datasæt, jo bedre, de lærer.
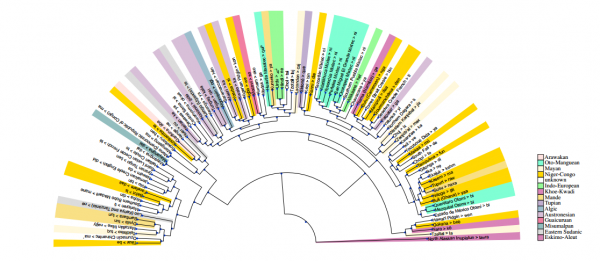
Et kort, der viser, hvordan den sidste tid, indikatorer klynge for 100 af de sprog, der er undersøgt.
Men disse enorme datasæt, der simpelthen ikke findes de fleste sprog. Det er derfor maskine oversættelse virker kun for en lille brøkdel af de mest almindelige lingos. Google Translate, for eksempel, kun taler om 90 sprog.
Så en vigtig udfordring for lingvister er at finde en måde til automatisk at analysere mindre fælles sprog bedre at kunne forstå dem.
I dag, Ehsaneddin Asgari og Hinrich Schutze på Ludwig-Maximilian-Universitetet i München i Tyskland siger, at de har gjort netop det. Deres nye strategi afslører vigtige elementer i næsten alle sprog, der kan derefter bruges som et springbræt for maskinoversættelse.
Den nye teknik, der er baseret omkring en enkelt tekst, der er oversat til mindst 2.000 forskellige sprog. Dette er Bibelen, og lingvister har længe erkendt dens betydning i deres disciplin.
Derfor har de skabt en database kaldet Parallel Bibelen Korpus, der består af oversættelser af det Nye Testamente i 1,169 sprog. Dette datasæt er ikke stor nok til den slags industrielle maskine lære at Google og andre udføre. Så Asgari og Schutze er kommet op med en anden tilgang, der er baseret på vej tider vises på forskellige sprog.
De fleste sprog bruger bestemte ord eller bogstav kombinationer til at betegne tider. Så den nye trick er at manuelt at identificere disse signaler på flere sprog, og så er brug af data-mining teknikker til at jage gennem andre oversættelser på udkig efter ord eller en streng af tegn, der spiller den samme rolle.
For eksempel, i dansk nutid er kendetegnet ved, at ordet “er” i fremtiden spændte af ordet “vil”, og det datid af ordet “var.” Selvfølgelig er der andre betegnere for.
Asgari og Schutze ‘ s idé er at finde alle disse ord i den engelske oversættelse af Bibelen sammen med andre eksempler fra en håndfuld andre oversættelser. Så se efter ord eller bogstaver strenge at spille den samme rolle, som i andre sprog. For eksempel, brev string “-ed”, der også betyder, datid i engelsk.
Men der er et twist. Asgari og Schutze ikke starte med engelsk, fordi det er en forholdsvis gamle sprog med mange undtagelser til den regel, som gør det svært at lære.
I stedet, de starter med et sæt af Kreolsk sprog, der har udviklet sig fra en blanding af andre sprog. Fordi de er yngre, Kreolske sprog har haft mindre tid til at udvikle disse sproglige særheder. Og det betyder, at de indeholder generelt bedre markører af sproglige træk, som anspændt. “Vores holdning er, at Kreolske sprog er mere regelmæssig end andre sprog, fordi de er unge og ikke har akkumuleret ‘historiske bagage”, som kan gøre beregningsmæssig analyse vanskeligere,” siger de.
Et af disse sprog er Seychellerne Creole, som bruger ordet “ti” for at betegne den sidste tid. For eksempel, “mon travay” betyder “jeg arbejder” i dette sprog, mens “mon ti travay”: “jeg har arbejdet” og “mon ti pe travay” betyder “jeg arbejdede.” Så “ti” er et godt tegn af datid.
Asgari og Schutze udarbejde en liste over datid betegnere i 10 andre sprog, og derefter mine Parallel Bibelen Corpus af andre ord og bogstav strenge, der udfører den samme funktion. De gentag dette for nutid og fremtid anspændt.
Resultaterne gør det til interessant læsning. Teknikken afslører lingvistik konstruktioner, der er relateret til anspændt i fælles sprog såsom “-ed” på engelsk og “te” på tysk, samt ord og sætninger, der udfører de samme funktioner i meget mindre fælles sprog, som i den sidste tid, betegner “den” i den Gourmanchema sprog fra Burkino Faso, og “yi” i Yalunka, der tales i Mali, og så videre.
Dette arbejde giver mulighed for forskerne til at oprette kort, der viser, hvordan sprog ved hjælp af lignende anspændt konstruktioner er knyttet (se diagram).
Det er interessant arbejde. Asgari og Schutze har udviklet en numerisk metode til at analysere den måde, folk bruger fortiden, nutiden, og fremtiden spændte på over 1.000 sprog. Dette er den største på tværs af sprog beregningsmæssige undersøgelse, der nogensinde er gennemført. Faktisk, antallet af sprog, der er involveret, er en størrelsesorden større end i andre undersøgelser.
Det arbejde har en betydelig ansøgning. Det sprog, der spændte maps giver mulighed for forskerne til hurtigt at træne forholdet mellem sprog og hvordan de er forbundet. Der kunne være brugt til bedre at forstå udviklingen af sprog.
Og den samme fremgangsmåde kan også anvendes til andre sproglige træk. “Vi kræver kun, at en sproglig funktion er åbenlyst markeret i et par af tusindvis af sprog som modsætning til at kræve, at det mærkes i alle sprog, i henhold til undersøgelsen,” siger Asgari og Schutze.
Konsekvenserne gå videre. Datalingvistik har haft en dybtgående indflydelse på vores forståelse af sprog, den måde, det er forskellig rundt omkring i verden, og hvordan maskiner kan forstå det. Denne nye disciplin har gjort det muligt automatisk at oversætte mange sprog direkte ind andre i skriftlig og mundtlig form. Faktisk, lover er, at øjeblikkelig maskine oversættelse vil snart match og derefter overgå evne menneskelige tolke.
Men nytten af maskinen oversættelse til visse sprog, der gør dem mere populære på bekostning af sprog, der ikke er taget højde for. Det er derfor maskine oversættelse kunne fremskynde lukningen af truede sprog.
Ja, lingvister har set et lignende fænomen med andre former for massekommunikation, såsom satellit-TV-tjenester. Disse er generelt broadcast i et enkelt sprog, som derefter bliver det mere attraktivt og populært end sprog, der ikke udsendes.
Asgari og Schutze arbejde kan medvirke til at ændre dette mønster af tilbagegang. Selvfølgelig, det er et stort skridt fra dette arbejde til præcise maskine oversættelse, men det er et skridt i den rigtige retning.
Ref: arxiv.org/abs/1704.08914: Fortid, Nutid, Fremtid: En Numerisk Undersøgelse af de Typer af Anspændt i 1.000 Sprog