 Bild: Universität an Albany, SUNY
Bild: Universität an Albany, SUNY
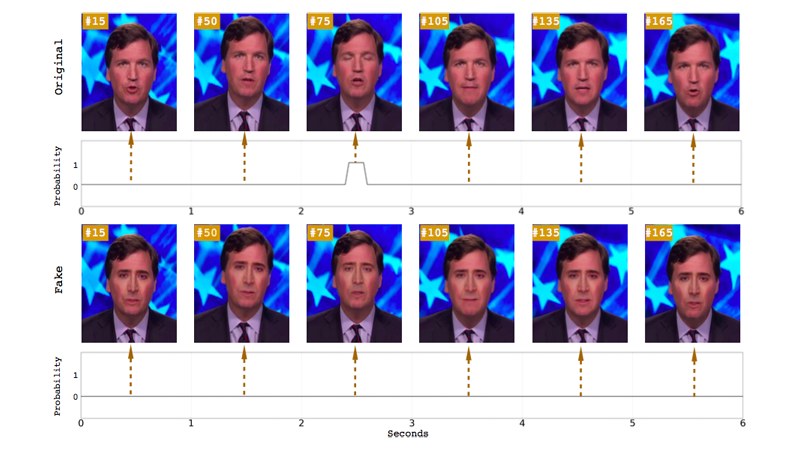
Die rate, mit der deepfake videos sind auf dem Vormarsch, ist beeindruckend und zutiefst verstörend. Doch die Forscher haben beschrieben eine neue Methode für den Nachweis ein “untrügliches Zeichen” dieser manipulierten videos, das ansehen einer person, das Gesicht auf den Körper eines anderen. Es ist ein Manko auch, dass die Durchschnittliche person würde feststellen: ein Mangel an zu blinken.
Forscher von der University at Albany, SUNY ‘ s computer science department veröffentlichte kürzlich ein Papier mit dem Titel “In Ictu Oculi: setzt man AI Generiert Gefälschte Gesicht Videos durch die Erkennung der Augen Blinzeln.” Das Whitepaper erfahren Sie, wie Sie kombiniert zwei neuronale Netze, um effektiver zu entlarven synthetisiert Gesicht videos, die oft übersehen “spontane und unwillkürliche physiologische Aktivitäten wie Atmung, Puls und die Augenbewegungen.”
Die Forscher beachten Sie, dass die mittlere Ruhe-Blinkrate für den Menschen ist 17 blinkt pro minute, das erhöht auf 26 blinkt pro minute, wenn jemand spricht, und verringert sich auf 4,5 blinkt pro minute, wenn Sie jemand liest. Die Forscher fügen hinzu, dass diese kleinen Unterschiede sind es Wert, Aufmerksamkeit zu schenken “, da viele von den “talking head” -Politiker sind wohl Lesen, wenn Sie aufgenommen werden.” Also wenn ein Thema in einem video nicht blinkt, ist es ein einfach sagen, dass das Filmmaterial nicht echt.
Es gibt einen Grund, Themen in deepfake videos nicht blinken: die Meisten Trainings-Datensätzen gefüttert, um neuronale Netzwerke enthalten keine geschlossenen Augen Fotos, wie Fotos von Menschen, die online veröffentlicht in der Regel zeigen Ihre Augen zu öffnen. Das ist Folge, da muss jemand sammeln Sie viele Fotos von einer Person in Reihenfolge zu erstellen ein deepfake von Ihnen, und dies kann getan werden durch eine open-source-Foto-scraping-tool, das packt öffentlich verfügbaren Fotos der target online.
Vorangegangenen Beiträge haben darauf hingewiesen, dass der Mangel an Auge-blinken als Möglichkeit zu erkennen, deepfakes, aber die University at Albany-Forscher sagen, dass Ihre system ist genauer als die bisher vorgeschlagenen Nachweismethoden. Frühere Studien verwendeten eye-Seitenverhältnis (OHR) oder ein convolutional neural network-basierten (CNN) Klassifikatoren, um zu erkennen, ob die Augen offen oder geschlossen waren. In diesem Fall kombinierten die Forscher die CNN-basierte Methode mit einer rekursiven neuronalen Netz (RNN), ein Ansatz der Auffassung, dass Vorherige Auge-Staaten zusätzlich zu den einzelnen frames des Videos.
Im Gegensatz zu einer rein CNN-Modell, die Forscher sagen, dass Ihre langfristige Wiederkehrende Convolutional Network (LRCN) Ansatz kann “effektiv vorherzusagen Augen Zustand, so dass es mehr glatt und präzise.” Laut dem Papier, hat dieser Ansatz eine Genauigkeit von 0,99, gegenüber CNN 0,98 und OHR 0.79.
Zumindest die Ergebnisse der Forscher signal, dass der machine-learning-Fortschritte, die es ermöglichte die Schaffung dieser ultrarealistic fake-videos können eine hand haben Sie vorzuführen. Aber deepfakes sind die Verbesserung noch erschreckend schnell. Zum Beispiel, ein neues system namens ” Deep Video-Porträts können eine Quelle Schauspieler manipulieren das portrait video von jemand anderem, und es erlaubt, für eine Reihe von physiologischen Signalen, einschließlich blinken und Auge blicken.
Es ist beruhigend zu sehen, Experten auf der Suche nach Möglichkeiten zu erkennen, echte videos von gefälschten, vor allem, da schlechte Schauspieler weiterhin Missbrauch der Technologie zu nutzen Frauen und potenziell Voraus, die Verbreitung von gefälschten Nachrichten. Aber es bleibt abzuwarten, ob diese Nachweismethoden wird schneller sein als die rasche Weiterentwicklung der deepfake tech. Und, mehr concerningly, wenn die Allgemeine öffentlichkeit wird sich auch die Zeit nehmen, sich zu Fragen, ob das video Sie sehen, real ist oder das Produkt von einem internet-troll.
“Meiner persönlichen Meinung nach, am wichtigsten ist, dass die Allgemeine öffentlichkeit muss sich bewusst sein, von den Möglichkeiten der modernen Technologie für die video-Generierung und-Bearbeitung,” Michael Zollhöfer, visiting assistant professor an der Stanford University, halfen bei der Entwicklung der Tiefen-Video-Porträts, schrieb in einem blog-post. “Dies ermöglicht es Ihnen, mehr zu denken kritisch über die video-Inhalte, die Sie jeden Tag verbrauchen, vor allem, wenn es gibt keinen Beweis der Herkunft.”
[h/t Das Registrieren]