In den letzten Jahren in dem Maße, wie Deep-learning-Systeme werden immer häufiger, die Wissenschaftler zeigten, wie die umstrittenen Proben beeinflussen können, was Sie wollen — von der einfachen Klassifikators Bilder bis hin zu Systemen für die Diagnose von Krebs — und sogar eine lebensbedrohende Situation. Trotz all Ihrer Gefahr, allerdings auch die umstrittene schlecht recherchiert. Und Wissenschaftler sind beunruhigt: ist es möglich, dieses Problem zu lösen?

Was ist adversarial attack (umstrittene Angriff)? Es ist Weg, um zu betrügen нейросеть, dass es gab ein ungültiges Ergebnis. Sie nutzen vor allem in der wissenschaftlichen Forschung, um die Nachhaltigkeit überprüfen zu unkonventionellen Modellen Angaben. Aber im wirklichen Leben Beispiele sind die änderung mehrerer Pixel in dem Bild von einem Panda so, dass нейросеть ist sich sicher, dass auf dem Bild — Gibbon. Obwohl die Wissenschaftler lediglich ergänzen das Bild «Rauschen».
Umstrittene Attacke: wie man нейросеть?
Das neue Werk des Massachusetts Institute of Technology weist auf einen möglichen Weg zur überwindung dieser Probleme. Entschieden Sie, könnten wir eine deutlich zuverlässigere Modelle, Deep learning, die wäre viel schwieriger zu manipulieren Weise boshaft. Aber lassen Sie uns zuerst betrachten wir die Grundlagen der umstrittensten Proben.
Wie Sie wissen, die Kraft des tiefen Lernens ergibt sich aus der ausgezeichneten Fähigkeit, Gesetzmäßigkeiten zu erkennen (Muster, Schablonen, Schema, Muster) in den Daten. Gib neuronales Netz Zehntausende von markierten Fotos von Tieren, und Sie erfährt, welche Verhaltensmuster im Zusammenhang mit dem Panda, und welche mit einem Affen. Dann kann Sie verwenden diese Muster für die Erkennung von neuen Bildern von Tieren, denen Sie zuvor nicht gesehen hatte.
Aber die Deep-learning-Modelle auch sehr zerbrechlich. Da das System der Erkennung der Bilder stützt sich nur auf Pixel-Muster, und nicht mehr auf konzeptionelle Verständnis von dem, was Sie sieht, ist es leicht zu täuschen, zu zwingen, Ihr zu sehen, etwas ganz anderes — nur auf eine bestimmte Weise zu brechen Muster. Ein klassisches Beispiel: fügen Sie ein wenig Lärm auf dem Bild von einem Panda, und das System Stuft Sie als Gibbon mit fast 100-prozentiger Sicherheit. Dieses Geräusch und wird dem umstrittenen Angriff.
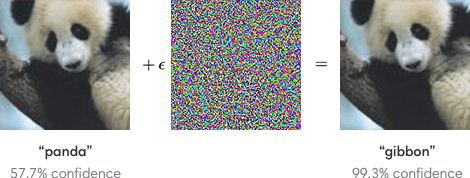
Seit einigen Jahren Wissenschaftler beobachteten dieses Phänomen, vor allem in Systemen Computer Vision, nicht wirklich zu wissen, wie man solche Schwachstellen. In der Tat, die Arbeit, die Letzte Woche auf einer großen Konferenz, gewidmet der Forschung der künstlichen Intelligenz — ICLR — die Frage der Zwangsläufigkeit umstrittenen Angriffe. Kann es scheinen, dass unabhängig davon, wie viele Bilder Sie Pandas gib Classifier Bilder, wird immer eine Art von Empörung, über die Sie das System kaputt macht.
Aber das neue Werk zeigt MIT, dass wir falsch spekuliert über die umstrittenen Angriffe. Anstatt zu kommen mit Möglichkeiten, um weitere qualitative Daten, mit denen das System speist, müssen wir grundlegend überdenken unser Ansatz für Ihre Ausbildung.
Die Arbeit zeigt diese Identifizierung ziemlich interessanten Eigenschaften umstrittensten Beispiele, die uns helfen zu verstehen, was der Grund für Ihre Wirksamkeit. Was ist der Trick: lässig, scheinbar Geräusche oder Aufkleber, die verwirrend нейросеть, eigentlich beschäftigen Sie sich sehr Punkt, kaum sichtbare Muster, die das System der Visualisierung stark ausgebildet assoziieren mit konkreten Objekten. Mit anderen Worten, die Maschine nicht ausfällt als bei Gibbon dort, wo wir den Panda. In der Tat, Sie sieht die regelmäßige Anordnung der Pixel, unaufdringliche Person, die viel häufiger erscheinen auf den Bildern mit den Gibbons als auf den Bildern mit den Pandas beim lernen.
Die Wissenschaftler demonstrierten das Experiment: Sie haben eine Reihe von Daten mit Bildern der Hunde, die alle so verändert werden, dass die Standard-Klassifikator Bilder fälschlicherweise identifizierte Sie als Katzen. Sie werden dann markiert diese Bilder «Katzen» und verwendet Sie für die Ausbildung von neuen neuronalen Netzwerk von Grund auf. Nach dem Training zeigten Sie нейросети Reale Bilder von Katzen, und es richtig identifizierte Sie alle als Katzen.
Die Forscher vermuten, dass in jedem Satz von Daten es gibt zwei Arten von Korrelationen: Vorlagen, die tatsächlich korrelieren mit der Bedeutung von Daten, Schnurrbart wie auf den Bildern mit Katzen oder Färbung von Fell auf den Bildern mit den Pandas, und Vorlagen, die es in die Trainingsdaten, aber keine Anwendung auf andere Kontexte. Diese letzten «irreführende» Korrelation, nennen wir Sie so gerade und werden in den umstrittenen Angriffen. Распознающая System, geschultes zu erkennen «irreführende» Vorlagen, findet Sie und glaubt, was man sieht, ist der Affe.
Dies sagt uns, dass wenn wir wollen beseitigen die Gefahr umstrittener Angriff, müssen wir ändern die Art und Weise der Ausbildung unserer Modelle. Derzeit lassen wir die neuronalen Netzwerks wählen Sie die Korrelation, die Sie verwenden wollen für die Identifizierung von Objekten im Bild. Als Ergebnis haben wir keinen Einfluss auf die Korrelation, die Sie findet, unabhängig davon, echte oder irreführende. Wenn, stattdessen, wir würden trainiert haben Ihr Modell erinnern nur die realen Vorlagen — gebunden auf die semantische Pixel — in der Theorie wäre es möglich, das produzieren von Deep-learning-Systems, die sich nicht verwirren.
Wenn die Wissenschaftler prüften diese Idee, indem Sie nur echte Korrelationen für die Ausbildung seiner Modelle an, die tatsächlich reduzierten Ihre Schwachstelle: Sie erliegen der Manipulation nur in 50% der Fälle, während das Modell, das auf wahren und falschen корреляциях, vergeblicher Versuch der Manipulation in 95% der Fälle.
Wenn, um eine kurze Zusammenfassung, von den umstrittenen Angriffen schützen können. Aber wir brauchen mehr Forschung, um Sie vollständig zu beseitigen.
Aber dann нейросеть nicht «betrügen». Gut oder schlecht? Erzählen Sie uns in unserem Chat in Телеграме.