Ryska specialister från Centrum för artificiell intelligens, AI Samsung Center-Moskva i samarbete med ingenjörer från brittiska Institute of science and technology har utvecklat ett system som kan skapa realistiska animerade bilder av ansikten på människor baserat på endast ett fåtal statiska bilder av en person. Vanligtvis i det här fallet kräver användning av stora databaser av bilder, men i utvecklarna av exempel, ett system som är utbildade för att producera en animerad bild av ett mänskligt ansikte, alla åtta stillbilder, och i vissa fall var tillräckligt och en. Mer information om den utveckling som redovisas i en artikel som publiceras i online-arkivet ArXiv.org.

Som en regel, att reproducera fotorealistiska personlig modul av det mänskliga ansiktet är ganska svårt på grund av den höga fotometriska, geometriska och en kinematisk komplexiteten i det mänskliga huvudet uppspelning. Anledningen är inte bara komplexiteten av modellering i ansiktet som en helhet (för detta finns det ett stort antal metoder modellering), men också komplexiteten i modellering särskilda egenskaper: mun, hår och så vidare. En annan komplicerande faktor är vår förmåga att upptäcka även små brister i den färdiga modellen av det mänskliga huvudet. Detta låg tolerans för fel simulering förklarar den nuvarande förekomsten av icke-fotorealistiska avatarer som används i telefonkonferenser.
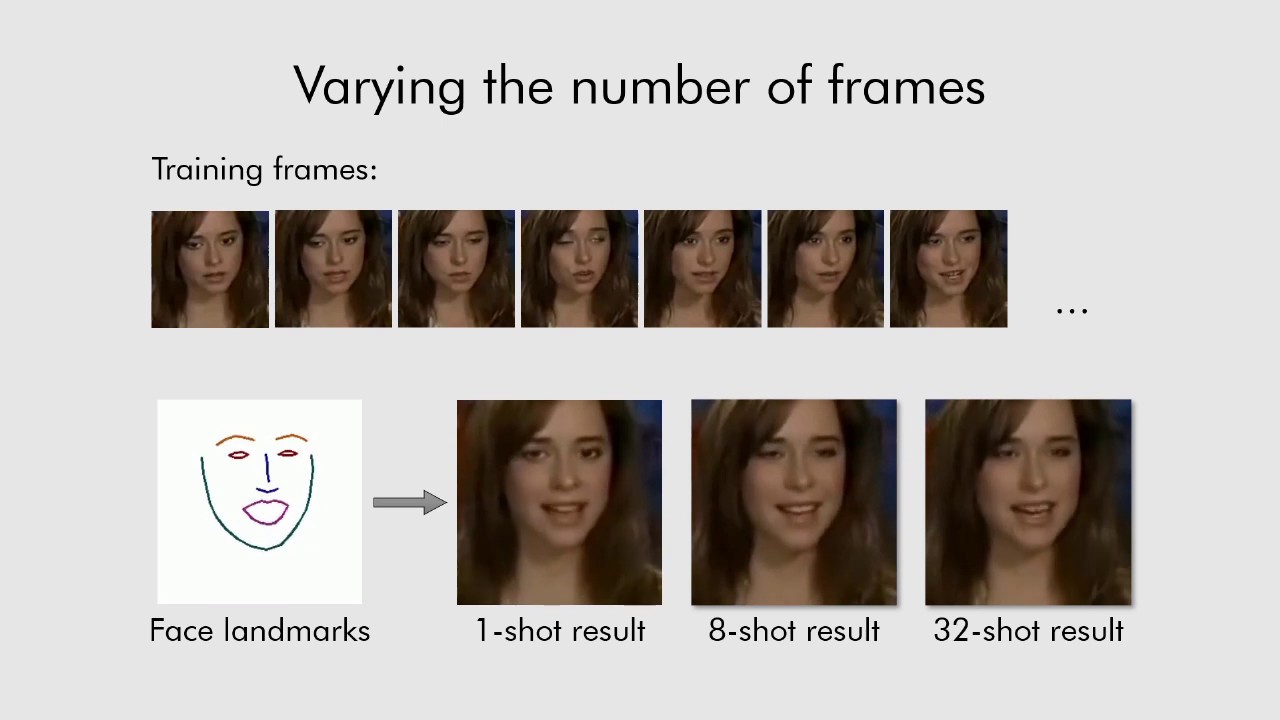
Enligt författarna, systemet, som kallas Fewshot lärande, kan skapa mycket realistiska modeller av talking heads människor och även porträtt. De algoritmer ger en sammanfattande bild i huvudet av en och samma person med rader av referens ansikte, som tagits från en annan bit av video, eller med hjälp av riktmärken i den andra personens ansikte. Som en källa till material för utbildning av systemutvecklare som används för en omfattande databas av videor av kändisar. För att få den mest exakta “talking head”, systemet behöver använda mer än 32 bilder.
För att skapa mer realistiska animerade bilder av ansikten används utvecklare tidigare utvecklingen i generativ-kontradiktoriskt modellering (GAN, där det neurala nätverket gissningar detaljerna i bilden, i effekt blir en konstnär), och även inställning av maskinen meta-lärande, där varje del av systemet är utbildade och utformad för att lösa ett specifikt problem.

Ordningen på meta-lärande


För behandling av statiska bilder över folks huvuden och göra dem till animerade används tre neurala nätverk: Embedder (nätverk genomförande) Generator (nät-generationen) och Diskriminerar (nätverk detektor). Den första delar upp en bild i huvudet (med grov facial landmärken) på vektorer för introduktion som innehåller oberoende av hållning information, den andra nätverk använder nätverket för genomförandet sevärdheter i ansiktet och genererar dem på grundval av nya uppgifter genom en uppsättning av convolutional lager som ger motstånd till förändringar i omfattning, förskjutningar, rotation, ändra perspektiv och andra störningar av den ursprungliga bilden av ansiktet. Och de nätverk som diskriminerar används för att bedöma kvaliteten och äktheten i de andra två nätverk. Som en följd av det system som omvandlar landmärken av ett mänskligt ansikte till realistiska letar personliga foton.


Utvecklarna betona att deras system är att kunna initiera parametrarna för nätverk generator, och de nätverk som diskriminerar individuellt för varje person i bilden, så att den lärande processen kan grundas endast på ett fåtal bilder, vilket ökar sin hastighet, även om den behöver för att välja de tiotals miljoner av parametrar.
För att diskutera nyheter i våra Telegram chatt.