
Kunstig intelligens. Hvor meget er sagt om ham, men vi endda sige, at det er ikke rigtig begyndt. Næsten alt, hvad du hører på udviklingen af kunstig intelligens, baseret på det gennembrud, der for tredive år. Vedligeholdelse fremskridt vil kræve bypass alvorlige begrænsninger alvorlige begrænsninger. Yderligere, i første person — James Somers.
Jeg står der, hvad der vil snart være verdens centrum, eller bare i et kæmpe værelse på syvende etage i en skinnende tårn i centrum af Toronto — som side for at se. Jeg er ledsaget af Jordan Jacobs, medstifter af dette sted: Institut for Vektor, som dette efterår åbner sine døre, og tegner til at blive den globale epicenter af kunstig intelligens.
Vi er i Toronto, fordi Geoffrey Hinton i Toronto. Geoffrey Hinton er far til dyb læring, teknikker, underliggende hype om emnet af AI. “I 30 år vil vi kigge tilbage og sige, at Jeff — Einstein AI, dyb læring, lige som vi kalder kunstig intelligens,” siger Jacobs. Af alle AI-forskere Hinton citeret oftere end de tre bag ham, og kombineret. De studerende og kandidater, der går på arbejde i AI lab, i Apple, Facebook og OpenAI; Sam Hinton, en førende forsker på Google Hjernen AI. Stort set enhver præstation inden for AI i løbet af de seneste ti år — i oversættelse, talegenkendelse, billede anerkendelse og spil — eller arbejde af Hinton.
Institut Vektor, dette monument til opstigningen af ideer, Hinton, er et forskningscenter, hvor virksomheder fra hele USA og Canada — som Google, Uber, og NVIDIA er ved at sponsorere den indsats, teknologi kommercialisering AI. Penge flow hurtigere end Jacobs formår at spørge om det; to af sine medstiftere interviewede virksomheder i Toronto, og den efterspørgsel for eksperter inden for AI var 10 gange højere end Canada leverer hvert år. Institut Vektor i en vis forstand untilled jomfru jorden for at forsøge at mobilisere verden omkring dybe læring: for at investere i denne teknik til at lære hende at finpudse og anvende. Datacentre er ved at blive bygget, skyskrabere er fyldt med nystartede virksomheder, til at deltage i en hel generation af studerende.
Når du står på gulvet, “Vektor”, man får følelsen af, at du er ved begyndelsen af noget. Men dyb læring, i sin essens, er meget gammel. Et gennembrud artikel af Hinton, skrevet sammen med David Rumelhart og Ronald Williams, blev udgivet i 1986. Værket beskriver i detaljer den metode, der er tilbage af udbredelse af fejl (backpropagation), “backprop” for korte. Backprop, ifølge John Cohen, er “alle baseret på, hvad dyb læring — alt”.
Hvis man ser på roden, i dag AI er dyb læring, og dybe læring er backprop. Og det er forbløffende, i betragtning af, at backprop mere end 30 år. For at forstå, hvordan det skete, blot har brug for: som det udstyr, der kunne vente så længe og så forårsage en eksplosion? Fordi når du lære historien om backprop, du vil forstå, hvad der sker med AI, og også, at vi kan ikke stå ved begyndelsen af revolutionen. Vi kan i sidste ende sig selv.
Gang fra Institut for Vektor i office Hinton på Google, hvor han tilbringer det meste af sin tid (han er nu Professor Emeritus ved University of Toronto) er en slags levende reklame for byen, i det mindste i sommer. Det bliver klart, hvorfor Hinton, der kommer fra ENGLAND, her flyttede i 1980’erne efter at have arbejdet i Carnegie Mellon University of Pittsburgh.
Måske er vi ikke i starten af revolutionen
Toronto — den fjerde største by i Nordamerika (efter Mexico city, new York og Los Angeles) og helt sikkert mere varieret: mere end halvdelen af befolkningen var født uden for Canada. Og dette kan ses, når man går rundt i byen. Mængden er multinationale. Der er gratis sundhedspleje og gode skoler, folk er venlige, den politik med hensyn til venstre og stabil; alt dette tiltrækker folk som Hinton, der siger, at han forlod USA på grund af “Irangate” (Iran-contra — en stor politisk skandale i Usa i anden halvdel af 1980-erne; derefter blev det kendt, at nogle medlemmer af den AMERIKANSKE administration organiserede hemmelige våben overførsler til Iran, hvilket er i strid med våbenembargoen mod landet). Dette begynder vores samtale før middag.
“Mange troede, at USA kunne invadere Nicaragua,” siger han. “På en eller anden måde troede, at Nicaragua hører til de Forenede Stater”. Han siger, at der for nylig har opnået et stort gennembrud i projektet: “jeg begyndte at arbejde Med en meget god Junior ingeniør”, en kvinde ved navn Sarah Sabur. Sabur Iranske, og hun blev nægtet et visum for at arbejde i Usa. Googles kontor i Toronto trak hende.
Den Hinton 69 år. Han er skarp, tynd engelsk ansigt med en tynd munden, store ører, og en stolt næse. Han blev født i Wimbledon, og i den samtale, der minder fortælleren i en børnebog om videnskab: en nysgerrig, lokkende, forsøger at forklare. Han er sjov og lidt galleriet. Det gør ondt at sidde på grund af rygproblemer, så kan han ikke flyve, og tandlægen lægger på den enhed, der ligner et surfbræt.

I 1980’erne, Hinton, som nu, en ekspert i neurale netværk, er betydeligt forenklet netværk model af neuroner og synapser af vores hjerne. Men på det tidspunkt var fast besluttet på, at det neurale netværk er en blindgyde i AI-forskningen. Selv om de første neurale netværk, “Perceptron” blev udviklet i 1960-erne, og det blev betragtet som et første skridt i retning af maskinen intelligens på menneskeligt niveau, i 1969 Marvin Minsky ‘ og Seymour Papert matematisk bevist, at sådanne netværk kan kun udføre de enkleste funktioner. Disse netværk havde to lag af neuroner: input og output lag. Netværk med et stort antal lag af neuroner mellem input og output, i teorien kunne løse en lang række problemer, men ingen vidste, hvordan man underviser dem, så at de i praksis var ubrugelige. På grund af “Perceptrons” fra idé af neurale netværk nægtede næsten alle med et par undtagelser, herunder Hinton.
Gennembrud Hinton i 1986 var at vise, at den metode, der er af fejl tilbage formering kan træne en dyb neurale netværk med antal lag mere end to eller tre. Men det tog endnu 26 år, før den øgede computerkraft. I den artikel af 2012 Hinton og to af hans studerende fra Toronto har vist, at dybe neurale netværk er uddannet med brug af backprop, skånede det bedste af det system af anerkendelse af billeder. “Deep learning” er begyndt at tage fart. Verden pludselig besluttet, at jeg vil tage over. For Hinton, det var en længe ventet sejr.
Reality distortion field af
Neurale netværk er sædvanligvis afbildet som en sandwich, hvis lag er overlejrede på hinanden. Disse lag indeholder kunstige neuroner, som er hovedsagelig repræsenteret af små computing-enheder, der er spændt, så spændt, som et fast neuron og overføre denne spænding til andre neuroner, som den er tilsluttet. Excitation af en neuron er repræsenteret med et nummer, siger, 0.13 eller 32.39, som bestemmer graden af excitation af neuron. Og der er en anden vigtig nummer på hver enkelt forbindelse mellem to neuroner, der definerer, hvor mange excitations, der skal overføres fra den ene til den anden. Dette antal modeller styrken af synapser mellem neuroner i hjernen. Jo højere tal, jo stærkere Association, som betyder mere spænding strømmer fra den ene til den anden.
En af de mest succesfulde anvendelser af dyb neurale netværk er mønstergenkendelse. I dag findes der programmer, der kan genkende, om det billede af hot dog. For ti år siden, at de var umulige. For at gøre det arbejde, du først nødt til at tage et billede. For nemheds skyld sige, det er sort-og-hvidt billede af 100 pixels med 100 pixels. Du fodrer det til et neuralt netværk, indstilling af magnetisering af hvert simuleret neuron i input-lag, så det er lige til lysstyrken af hver pixel. Dette er det nederste lag af sandwich: 10,000 neuroner (100 x 100), hvilket svarer til lysstyrken af hver enkelt pixel i billedet.
Så er denne store lag af neuroner der er forbundet til et andet stort lag af neuroner, som allerede ovenfor, sige et par tusind, og de til gengæld til et andet lag af neuroner, men mindre, og så videre. Endelig, det øverste lag af sandwich lag output består af to neuroner, repræsenterer en “hot dog” og den anden som “ikke en hot dog”. Ideen er at træne et neuralt netværk til at vække kun den første af disse neuroner, hvis billedet er en hot dog, og for det andet, hvis der ikke. Backprop, den metode, der er af fejl tilbage formering, som Hinton har bygget sin karriere at gøre netop det.
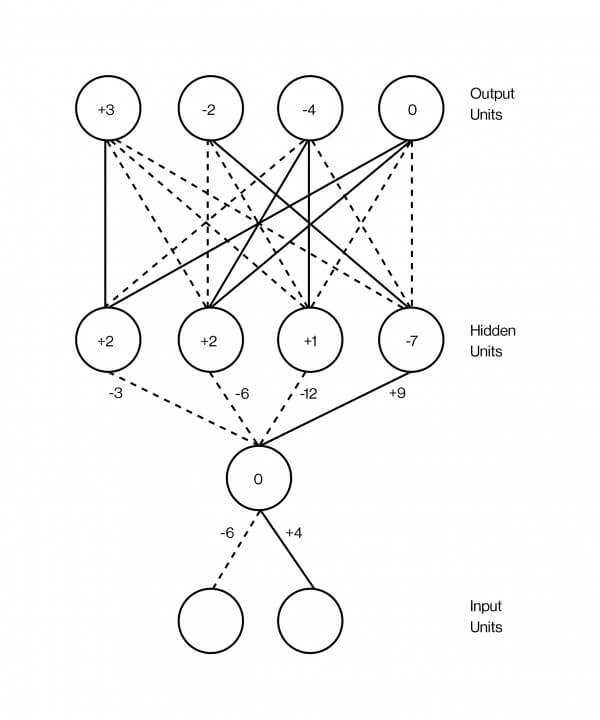
Backprop er meget simpelt, men det virker bedst med enorme mængder af data. Det er derfor, big data er så vigtige, at AI, hvorfor de så ivrigt engageret i Facebook og Google, og hvorfor Vektor Institut besluttet at etablere kontakt med fire førende hospitaler i Canada og udveksling af data.
I dette tilfælde de oplysninger, tage form af en million billeder, nogle hotdogs, nogle uden, det trick er at markere disse billeder, så der hotdogs. Når du opretter et neuralt netværk for første gang, forbindelser mellem neuroner er tilfældige vægt tilfældige tal til at sige, hvor meget excitation overføres gennem hver enkelt forbindelse. Hvis hjernens synapser er endnu ikke konfigureret. Formålet med backprop til at ændre disse vægte, således at netværket op at køre: så når du passerer et billede af en hot dog på det nederste lag, den neuron “hot dog” i det øverste lag er begejstret.
Antag, at du tager den første træning et billede af et klaver. Du omdanne intensiteten af pixel billede med 100 x 100 10,000 numre, ét for hver neuron i det nederste lag-netværk. Så snart excitation er distribueret over et netværk i overensstemmelse med forbindelsen styrken af neuroner i de tilstødende lag, gradvist frem til det sidste lag, der er en af de to neuroner, der bestemmer billede af hot dog. Fordi det er et billede, med et klaver, neuron “hot dog” skal vise nul, og neuron er “ikke en hot dog”, skal vise tallet højere. For eksempel, det virker ikke sådan. For eksempel netværket var galt med det billede. Backprop er proceduren for at styrke styrken af hver enkelt forbindelse i netværket, så du har mulighed for at rette fejlen i eksemplet med at lære.
Hvordan virker det? Du begynder med de sidste to neuroner, og finde ud af, hvordan de er forkert på den: hvad er forskellen mellem deres tal for excitation, og hvad det bør være, virkelig. Så kan du se hver forbindelse, der fører til disse neuroner — faldende lavere lag, og bestemme deres bidrag til fejl. Du holde gør dette, indtil du når det første sæt af forbindelser på bunden af netværket. På dette punkt er, du ved, hvad der er bidrag af de enkelte forbindelser i den samlede fejl. Endelig, kan du ændre alle de vægte, for at mindske risikoen for fejl. Denne såkaldte “metode tilbage formering af fejlen” ligger i, at du gerne sende fejl tilbage gennem netværket, startende fra den modsatte ende med exit.
Utrolig begynder at ske, når du gør dette med millioner eller milliarder af billeder på nettet bliver godt definere, billedet af hot dog eller ikke. Og hvad der er endnu mere bemærkelsesværdigt er det faktum, at de enkelte lag af disse netværk, billede anerkendelse begynde at se billeder af de samme, som gør vores egen visuelle system. Det er det første lag, der registrerer konturerne af neuroner vil skyde, når de konturer, og er ikke begejstrede, når de ikke er; det næste lag definerer sæt af kanter, hjørner; det næste lag begynder at skelne former; det næste lag finder alle mulige emner som “åben rolls” eller “ruller lukkede”, fordi det aktiverer det relevante neuroner. Netværket er organiseret i hierarkiske lag, selv uden at være programmeret.
Ægte intelligens ikke tøve, når problemet er lidt anderledes.
Dette er, hvad der så imponeret alle. Det er ikke så meget det faktum, at neurale netværk er godt klassificeret billede med hotdogs: de opbygge repræsentationer af ideer. Med tekst, dette bliver endnu mere indlysende. Du kan fodre udgave af Wikipedia, mange milliarder af ord, simple neurale netværk at lære hende at give hvert ord med numre, der svarer til den excitations for hver neuron i det lag. Hvis du forestille dig alle disse numre er koordinater i den komplekse plads, skal du finde et punkt, der er kendt i denne sammenhæng som en vektor, for hvert ord i dette rum. Så skal du træne netværket, således at de ord, der vises på sider i Wikipedia, vil være udstyret med samme koordinater — og voila, er noget mærkeligt sker: ord, der har de samme værdier, der vises tæt på denne plads. “Gale” og “frustreret” ville være tæt ved; “tre” og “seven”. Desuden vektor regning gør det muligt at trække vektor “Frankrig” fra “Paris”, skal du tilføje den til “Italien” og find “Rom” i nærheden. Ingen sagde, at neurale netværk, Rom i Italien er det samme som Paris, Frankrig.
“Det er fantastisk,” siger Hinton. “Det er chokerende”. Neurale netværk kan ses som et forsøg på at tage ting — billeder, ord, optage samtaler, journaler — og at sætte dem i, som matematikere sige, multi-dimensional vektor rum, hvor den nærhed eller afsides ting vil afspejle de vigtigste aspekter af den virkelige verden. Hinton mener, at det er, hvad hjernen gør. “Hvis du ønsker at vide, hvad der er den idé,” siger han, ” jeg kan give det til dig serie af ord. Jeg kan sige, “John tænkte, at “ups.” Men hvis du spørger: hvad er den idé? Hvad betyder det for John at have denne idé? Efter alt, i hans sind, ingen åbning af citater, “ups”, afsluttende anførselstegn, Generelt er det ikke tæt. I hans hoved kører en slags neural aktivitet”. Flotte billeder af neural aktivitet, hvis du gør det math det er muligt at fange i vektorrum, hvor aktiviteten af enkelte neuroner, ville svare til et nummer, og hvert nummer er en koordinat på en meget stor vektor. Ifølge Hinton, ideen er en dans af vektorer.
Nu forstår jeg hvorfor Institute of Vector hedder?
Hinton skaber et felt af forvrængning af virkeligheden, du i første omgang får en følelse af tillid og entusiasme, inspirerende selvtillid i det faktum, at de for vektorer, intet er umuligt. I den sidste ende, har de allerede skabt selvkørende biler at opdage kræft computere, instant oversættere af det talte sprog.
Og kun når du forlader værelset, skal du huske på, at disse systemer “dyb læring” er stadig temmelig dum, på trods af deres demonstrative tankens magt. Den computer, der ser en masse af bagværk på bordet og automatisk tegn på, det som “en flok af donuts liggende på bordet” synes at forstå verden; men når det samme program ser en pige, der børster hendes tænder og siger, at det er “drengen med et baseball-bat”, er du klar over hvordan flygtig denne forståelse, hvis det nogensinde er.
Et neuralt netværk er blot en tankeløs og vage billeder af genkendere, og hvor nyttigt det kan være sådan genkendere billeder — på grund af deres stræber efter at integrere i et software — de ved bedst repræsenterer en begrænset race af intelligens, der er let at snyde. Dybt neurale netværk, der genkender billedet, kan man blive helt forvirret, hvis du ændrer én pixel, eller tilføje visuelle støj, der opfattes af mennesker. Næsten lige så ofte som vi finde nye måder at bruge dyb læring, vi ofte støder på sine begrænsninger. Selvkørende biler ikke kan køre i tilstande, som ikke har set før. Maskiner kan ikke stille forslag, der kræver en fælles mening og forståelse af, hvordan verden fungerer.

Dyb læring i en vis forstand efterligner, hvad der sker i den menneskelige hjerne, men på en overfladisk måde — hvilket kan forklare, hvorfor hans intelligens er så overfladiske tider. Backprop ikke blev opdaget i færd med at dyppe i hjernen forsøg på at dechifrere den meget idé; det voksede ud af modeller af dyr læring af trial and error i en gammeldags eksperimenter. Og de fleste af de vigtige skridt, der er blevet gjort siden starten, indeholder ikke noget nyt om motivet for neurobiologi; det var en teknisk forbedring, velfortjent års arbejde, matematikere og ingeniører. Hvad vi ved om intelligens, intet i forhold til hvad vi endnu ikke ved.
David Duvant, assisterende Professor i samme Afdeling, og Hinton, University of Toronto, siger, at den dybe læring synes at engineering introduktion til fysik. “Der er nogen, skrev arbejde og sagde: “jeg gjorde denne bro, og han står!”. En anden skriver: “jeg lavede denne bro, og det kollapsede, men jeg har tilføjet en support-og det er det værd.” Og de gå amok på den understøtter. Nogen tilføjer arch og alle, arch er cool! Med fysik du kan faktisk forstå, hvad de vil arbejde med og hvorfor. Vi har først for nylig begyndt at gå i det mindste en forståelse af kunstig intelligens”.
Og Professor Hinton siger: “de fleste konferencer tale om indførelse af små ændringer i stedet for at skulle til at tænke og wonder, “Hvorfor det, vi gør nu ikke virker? Hvad er årsagen? Lad os fokusere på det.”
Udsigten fra ydersiden er svært at producere, når alt, hvad du ser, er en kampagne for en forfremmelse. Men de seneste fremskridt inden for AI, at en mindre grad var en videnskab, og flere af engineering. Selv om vi bedre forstå, hvilke ændringer der vil forbedre systemet for dyb læring, har vi vagt forestille sig, hvordan disse systemer fungerer, og om de nogensinde vil møde noget, der er så kraftfuld som det menneskelige sind.
Det er vigtigt at forstå, har vi været i stand til at udvinde alt, hvad du kan fra backprop. Hvis Ja, så forventer vi et plateau i udviklingen af kunstig intelligens.
Tålmodighed
Hvis du ønsker at se det næste gennembrud, en slags grundlag for en meget mere fleksibel intelligens, bør du i teorien, henvises der til undersøgelser, som svarer til den undersøgelse af backprop i 80 år: når kloge mennesker give op, fordi deres idéer endnu ikke var i arbejde.
For et par måneder siden, jeg besøgte Center for Bevidsthed, Hjerner og Maskiner, mp-facilitet, der har til huse på MIT, for at se, hvordan min ven Eyal Dechter forsvarer sin afhandling om kognitiv videnskab. Før forestillingen, hans kone, Amy, hans hund ruby og hans datter Suzanne har støttet ham, og ønskede ham held og lykke.
Den Eyal begyndte sin tale med et fascinerende spørgsmål: hvordan er det, at Suzanne, der er kun to år, lærte at tale, til at spille, for at følge historier? I den menneskelige hjerne, sådan at det giver ham mulighed for at studere? Lære om computer nogensinde vil lære så hurtigt og gnidningsløst?
Vi forstå nye fænomener, i form af ting, vi allerede forstår. Vi bryder domæne i stykker og studere stykker. Den Eyal er en matematiker og programmør, han mener om den opgave — for eksempel lave en soufflé — how om komplekse computer programmer. Men du behøver ikke lære at lave en soufflé med at huske hundredvis af små instruktion som “drej til albuen 30 grader, så kig på køkkenbordet, og derefter trække din finger, så…”. Hvis du skulle gøre, at der i hver ny sag, uddannelse ville være utåleligt, og du ville blive stoppet i udvikling. I stedet vil vi se programmet skridt på højeste niveau som “pisk æggehvider”, som selv består af underprogrammer, som “bryde æg og adskille de hvide fra æggeblommer”.
Computere, der ikke gør, og derfor ser dumt ud. Til dyb læring anerkendt hot dog, du er nødt til at fodre hende 40 millioner billeder af hot dogs. Bandet Suzanne lært af hot dog, bare vis hende hot dog. Og længe før, at det vil have en forståelse af de sprog, som går meget dybere anerkendelse af forekomsten af de enkelte ord sammen. I modsætning til den computer i hendes hoved en idé om, hvordan verden fungerer. “Det overrasker mig, at folk er bange for, at computere vil tage deres job,” siger Eyal. “Computere kan erstatte advokater, ikke fordi advokater gør noget kompliceret. Men fordi advokater, der lytter og taler med folk. I denne forstand er vi meget langt væk fra det hele”.
Ægte intelligens vil ikke tøve, hvis du ændrer lidt krav til løsningen. Og den centrale tese, Eyal var en demonstration, der, i princippet, hvordan man kan gøre en computer til at køre således: i live anvende alle, at han allerede kender til nye udfordringer, hurtigt forstå på farten, til at blive ekspert på et helt nyt område.
I virkeligheden, denne procedure, som han kalder den algoritme “forskning-komprimering”. Det giver computeren en funktion programmør samle et bibliotek af genanvendelige modulære komponenter, der giver dig mulighed for at oprette mere komplekse programmer. At vide noget om nye domæne, som computeren forsøger at strukturere viden om ham, at blot at studere hans konsolidere opdaget og derefter studere som et barn.
Hans Rådgiver, Joshua Tenenbaum, en af de mest citerede forskere inden for AI. Navnet på Tenenbaum pop op i halvdelen af de samtaler jeg har haft med andre forskere. Nogle af de centrale folk på DeepMind — team AlphaGo, der slog den legendariske world champion på spil gå i 2016 — han arbejdede under ham. Han er involveret i en start, som forsøger at give selvkørende biler, intuitiv forståelse af grundlæggende fysik og intentioner for andre bilister for at blive bedre til at forudse dem, der forekommer i situationer, der ikke tidligere har stået over for.
Specialet af Eyal har endnu ikke været anvendt i praksis, selv i programmer, der ikke var indført. “Problemer på Eyal, en meget, meget svært,” siger Tenenbaum. “Vi er nødt til at få overført en masse af generationer.”
Når vi sad ned for at drikke en Kop kaffe, Tenenbaum sagde, der udforsker historien om backprop for inspiration. I årtier, backprop var en manifestation af cool matematik, for det meste i stand til intet. Så snart computere blev hurtigere, og hårdere, ændrede alt sig. Han håbede, at noget lignende vil ske med hans egne værker og værker af hans elever, men “det kan tage et par årtier.”
Som for Hinton, han er overbevist om, at overvinde de begrænsninger af AI, der er forbundet med oprettelsen af en “bro mellem datalogi og biologi”. Backprop, fra dette synspunkt, var en triumf for biologisk inspireret design; den idé, der oprindeligt kom ikke fra teknik og fra psykologi. Så nu Hinton forsøger at gentage dette trick.
I dag neurale netværk er sammensat af stort fladskærms lag, men i den menneskelige neocortex, disse neuroner er arrangeret ikke kun horisontalt, men også vertikalt, i kolonner. Hinton ved, hvorfor vi har brug for sådan kolonner i et syn, for eksempel, de gør det muligt at genkende objekter, selv hvis du ændrer synspunkt. Så han skaber en kunstig udgave — og kalder dem “kapsler” til at teste denne teori. Men det virker ikke: kapsel er ikke særlig forbedret ydeevne af sine netværk. Men for 30 år siden bactrobam var det samme.
“At skulle gøre det,” siger han om teorien for kapsler, og griner af sin egen arrogance. “Og hvad virker ikke endnu, dette er kun en midlertidig irritation.”
Materialer Medium.com
Kunstig intelligens Geoffrey Hinton: far til “dyb læring”
Ilya Hel