
Artificiell intelligens. Hur mycket är sagt om honom, men vi ens säga det har inte riktigt börjat. Nästan allt du hör om utvecklingen av artificiell intelligens, baserat på genombrott, som trettio år. Att upprätthålla framsteg kommer att kräva kringgå allvarliga begränsningar allvarliga begränsningar. Ytterligare, i första person — James Somers.
Jag står där, vad som snart kommer att vara i centrum av världen, eller bara i ett stort rum på sjunde våningen i ett glänsande torn i centrala Toronto — vilken sida för att se. Jag är tillsammans med Jordanien Jacobs, en av grundarna av denna plats: Institutet för Vektor, som i höst öppnar sina dörrar och lovar att vara den globala epicentret av artificiell intelligens.
Vi är i Toronto, eftersom Geoffrey Hinton i Toronto. Geoffrey Hinton är far till djupinlärning, tekniker, underliggande hype på föremål av AI. “I 30 år kommer vi titta tillbaka och säga att Jeff — Einstein-AI, djupt lärande, precis som vi kan kalla för artificiell intelligens, säger Jacobs. Av alla AI-forskare Hinton citeras oftare än de tre bakom honom, tillsammans. Dess studenter och akademiker gå till jobbet i AI lab i Apple, Facebook och OpenAI; Sam Hinton, en ledande forskare på Google Hjärnan AI. Praktiskt taget alla prestation inom AI under de senaste tio åren — i översättning, taligenkänning, bildigenkänning och spel — eller arbetar i Hinton.
Institutet Vektor, detta monument till bestigningen av idéer för Hinton, är ett forskningscentrum där företag från hela USA och Kanada — som Google, Uber, och NVIDIA är med och sponsrar insatser för kommersialisering av teknik AI. Pengarna flöda snabbare än Jacobs klarar av att be om det, två av dess grundare intervjuade företagen i Toronto och efterfrågan på experter inom AI var 10 gånger högre än Kanada levererar varje år. Institutet Vektor i en känsla untilled jungfrulig mark för att försöka mobilisera världen runt djupt lärande: i syfte att investera i denna teknik för att lära henne att finslipa och tillämpa. Datacenter byggs skyskrapor är fylld med startups att delta i en hel generation av studenter.
När du står på golvet med “Vector”, man får känslan av att du är i början av något. Men djupt lärande, i sitt väsen, mycket gammal. Ett genombrott artikel av Hinton, skriven tillsammans med David Rumelhart och Ronald Williams, publicerades 1986. Det arbete som i detalj beskriver metoden för tillbaka förökning av fel (backpropagation), “backprop” för kort. Backprop, enligt John Cohen, är “allt baserat på vad djupt lärande — allt”.
Om du tittar på roten, idag AI är djupt lärande, djupt lärande är backprop. Och det är helt otroligt, med tanke på att backprop mer än 30 år. För att förstå hur det hände, bara behöver: utrustning kunde vänta så länge och då orsaka en explosion? Eftersom när du lär dig historien om backprop, du kommer att förstå vad det är som händer med AI, och också att vi inte får stå i början av revolutionen. Vi får i slutet själv.
Promenad från Institutet för Vektor i office Hinton på Google, där han tillbringar det mesta av sin tid (han är nu Professor Emeritus vid University of Toronto) är en typ av levande reklam för staden, åtminstone på sommaren. Blir det klart varför Hinton, som härstammar från STORBRITANNIEN, flyttade hit i 1980-talet efter att ha arbetat på Universitetet Carnegie Mellon i Pittsburgh.
Kanske är vi inte i början av revolutionen
Toronto — den fjärde största staden i Nordamerika (efter Mexico city, new York och Los Angeles) och säkert mer varierad: mer än hälften av befolkningen som var födda utanför Kanada. Och detta kan ses när du går runt i staden. Publiken är multinationella. Det är gratis hälso-och sjukvård och bra skolor, människor är vänliga, policy med avseende på vänster och stabil; allt detta lockar människor som Hinton, som säger att han lämnade USA på grund av “Irangate” (Iran-contra — en stor politisk skandal i Usa under andra halvan av 1980-talet, då det blev känt att vissa medlemmar av den AMERIKANSKA administrationen organiserade hemliga vapenleveranser till Iran, och bryter därmed mot vapenembargot mot landet). Här börjar vårt samtal innan middagen.
“Många trodde att USA skulle invadera Nicaragua”, säger han. “De på något sätt trodde att Nicaragua hör till Förenta Staterna”. Han säger att han har gjort ett stort genombrott i projektet: “jag började arbeta Med en mycket bra Junior ingenjör”, en kvinna som heter Sarah Tobias. Tobias Iranska, och hon blev nekad visum för att arbeta i Usa. Googles kontor i Toronto drog henne.
Den Hinton 69 år. Han har kraftiga, tunna engelska ansiktet med en tunn mun, stora öron och en stolt näsa. Han var född i Wimbledon och i samtalet påminner berättaren av ett barns bok om vetenskap: en nyfiken, lockande, att försöka förklara. Han är rolig och lite spel för gallerierna. Det gör ont att sitta på grund av problem med ryggen, så han kan inte flyga, och tandläkaren lägger på den enhet, som liknar en surfbräda.

På 1980-talet, Hinton var, då som nu, en expert på neurala nätverk, är avsevärt förenklat nätet modell av neuroner och synapser i vår hjärna. Men på den tiden, det var fast beslutade att neurala nätverk är en återvändsgränd i AI-forskning. Även om den första neurala nätverk, “Perceptron” utvecklades på 1960-talet och det ansågs vara ett första steg mot en maskin intelligens på den mänskliga nivån, 1969 Marvin Minsky och Seymour Papert matematiskt bevisat att sådana nätverk kan endast utföra de enklaste funktionerna. Dessa nätverk hade två lager av neuroner: input layer-och utgående lager. Nätverk med ett stort antal lager av nervceller mellan input och output kan, i teorin, lösa en rad olika problem, men ingen visste hur man lär ut dem, så att de i praktiken var värdelösa. På grund av “Perceptrons” från idé av neurala nätverk vägrade nästan alla med ett fåtal undantag, inklusive Hinton.
Genombrott Hinton 1986 var att visa att den metod som av misstag tillbaka förökning kan träna en djup neurala nätverk med flera lager mer än två eller tre. Men det tog ytterligare 26 år innan ökad datorkraft. I den artikel av 2012 Hinton och två av hans elev från Toronto har visat att djup neurala nätverk tränas med hjälp av backprop, skonade det bästa av system för igenkänning av bilder. “Djupt lärande” har börjat ta fart. Världen plötsligt bestämde sig för att AI kommer att ta över. För Hinton, det var en efterlängtad seger.
Reality distortion field av
Neurala nätverk är oftast avbildas som en smörgås vars lager är överlagrat på varandra. Dessa lager innehåller artificiella neuroner, som är i huvudsak representeras av små datorer enheter som är glada — glada av en riktig nervcell och skicka detta spänning till andra nervceller med vilken den är ansluten. Excitation av en neuron representeras av ett nummer, säga, 0.13 eller 32.39, som avgör graden av excitation av neuronen. Och det finns en annan viktig antal vid varje anslutning mellan två nervceller, som definierar hur många excitationer som ska överföras från en till en annan. Detta antal modeller styrkan av synapser mellan nervceller i hjärnan. Ju högre nummer, desto starkare Association, vilket innebär mer spänning flöden från en till en annan.
En av de mest framgångsrika program av djup neurala nätverk är mönsterigenkänning. Idag finns det program som kan känna igen om bilden av hot dog. För tio år sedan de var omöjliga. För att få det att fungera, måste du först ta en bild. För enkelhetens skull säga att det är en svart-vit bild av 100 x 100 pixlar. Du foder till ett neuralt nätverk, där excitation av varje simulerad neuron i inmatningslagret så att det motsvarar ljusstyrkan för varje pixel. Detta är den nedre skiktet av smörgås: 10,000 nervceller (100 x 100), vilket motsvarar ljusstyrkan för varje pixel i bilden.
Då detta stora lager av nervceller som är ansluten till en annan stort lager av nervceller, som redan ovan, säg, ett par tusen, och de, i sin tur, till ett annat lager av neuroner, men mindre, och så vidare. Slutligen, det översta lagret av smörgås lager produktionen kommer att bestå av två neuroner, en som representerar det “hot dog” och andra som “inte ett hot dog”. Tanken är att träna ett neuralt nätverk för att excitera det endast den första av dessa neuroner, om bilden är en hot dog, och för det andra, om någon. Backprop, den metod som av misstag tillbaka förökning, som Hinton har byggt sin karriär bara att göra det.
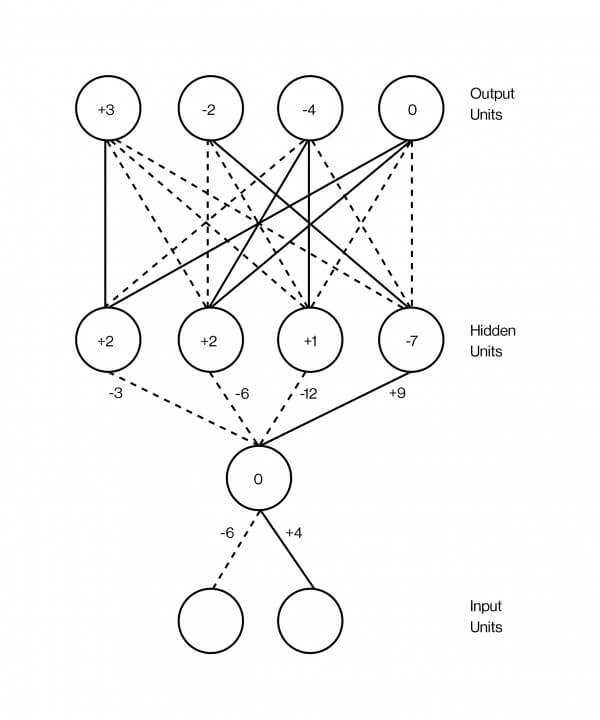
Backprop är mycket enkelt, även om det fungerar bäst med stora mängder data. Det är därför big data är så viktigt att AI därför de så ivrigt engagerade i Facebook och Google och varför Vektor Institutet bestämde sig för att etablera kontakt med fyra ledande sjukhus i Kanada och för att utbyta data.
I detta fall, data tar form av en miljon bilder, några heta hundar, vissa utan, tricket är att markera dessa bilder med korv. När du skapar ett neuralt nätverk för första gången, kopplingar mellan nervceller är slumpmässiga vikt slumptal för att säga hur mycket excitation överförs genom varje anslutning. Om hjärnans synapser som inte ännu konfigurerats. Syftet med backprop att ändra dessa vikter så att nätverket igång: så när du passerar en bild av en hot dog på det understa lagret, neuron “hot dog” i det översta skiktet är glada.
Antag att du tar den första utbildningen en bild av ett piano. Du förändra intensiteten av pixel bild 100 x 100 10,000 siffror, en för varje neuron i det nedre lagret för nätverket. Så snart excitation är distribuerade över ett nätverk i enlighet med styrkan på anslutningen av nervceller i den intilliggande lager, gradvis når den sista lagret, en av de två nervceller som avgör bilden av hot dog. Eftersom det är en bild med ett piano, en neuron “hot dog” måste visa noll, och neuron är “inte ett hot dog” måste visa antalet högre. Till exempel, det fungerar inte som det. Till exempel nätet var fel om bilden. Backprop är förfarandet för att stärka styrka för varje anslutning i nätverket, så att du kan korrigera felet i exempel på lärande.
Hur fungerar det? Du börjar med de sista två nervceller och räkna ut hur de är fel: vad är skillnaden mellan deras nummer av excitation och vad det ska vara, egentligen. Då kan du visa varje anslutning, leder till att dessa nervceller — fallande lägre lager och bestämma deras bidrag till felet. Du fortsätt att göra detta tills du når den första uppsättning anslutningar på undersidan av nätverket. Vid denna punkt, du vet, vad som är bidrag enskilda föreningar i totalt fel. Slutligen, du kan ändra alla vikter för att minska risken för fel. Denna så kallade “metod för tillbaka förökning av felet” ligger i det faktum att du gillar att skicka fel tillbaka genom nätverket, från den omvända avsluta med exit.
Otroligt börjar att hända när du gör detta med miljontals eller miljarder bilder på nätet blir väl definiera bilden av hot dog eller inte. Och vad som är ännu mer anmärkningsvärt är det faktum att de enskilda skikten av dessa nätverk, bildigenkänning börja se bilder densamma som gör våra egna visuella systemet. Det är den första lager upptäcker konturerna av nervceller aktiveras när konturerna är och är inte glada när de inte är, nästa lager definierar uppsättningar av kanter, hörn, nästa lager börjar urskilja former, nästa lager finner alla typer av objekt som “öppna rullar” eller “rullar stängt”, eftersom den aktiverar rätt nervceller. Nätverket är organiserat i hierarkin, även utan att vara programmerade.
Verklig intelligens inte tveka, när problemet är något annorlunda.
Detta är vad så imponerad av alla. Det är inte så mycket det faktum att neurala nätverk är väl klassificeret bild med hot dogs: de bygger representationer av idéer. Med text, detta blir ännu mer uppenbart. Du kan mata text från Wikipedia, många miljarder ord, enkla neurala nätverk för att lära henne att förse varje ord med nummer som motsvarar de excitationer för varje nervcell i lager. Om man tänker sig alla dessa siffror är koordinaterna i det komplexa utrymme, kan du hitta en punkt är känd i detta sammanhang som en vektor, för varje ord i detta utrymme. Då du tränar nätverket så att orden förekommer på nästa sidor på Wikipedia, kommer att vara utrustad med liknande koordinater — och voila, något konstigt händer: ord som har liknande värden visas i nära denna plats. “Mad” och “frustrerade” skulle vara i närheten, “tre” och “sju”. Dessutom, aritmetisk gör det möjligt att subtrahera vektor “Frankrike” från “Paris”, lägg till det till “Italien” och hitta “Rom” i närheten. Ingen sa neurala nätverk, Rom i Italien är den samma som Paris i Frankrike.
“Det är fantastiskt”, säger Hinton. “Det är chockerande”. Neurala nätverk kan ses som ett försök att ta saker — bilder, ord, spela in samtal, medicinska journaler och att sätta dem i, som matematiker säga, en flerdimensionell vektor utrymme i vilket den närhet eller avlägsenhet saker kommer att spegla de viktigaste aspekterna av den verkliga världen. Hinton tror att det är vad hjärnan gör. “Om du vill veta vad som är tanken, säger han,” jag ger det till dig-serien av ord. Jag kan säga, “John tänkte, “oj då.” Men om du frågar: vad är tanken? Vad betyder det för John att få denna idé? Efter alla, i hans sinne, ingen öppning citat, “oops”, avslutande citattecken, detta är i Allmänhet inte nära. I hans huvud driver en typ av neural aktivitet”. Stora bilder av neural aktivitet, om du gör matten, det är möjligt att fånga i vector space, där aktiviteten av varje neuron skulle motsvara ett nummer och varje nummer är en koordinat på ett mycket stort vektor. Enligt Hinton, tanken är en dans av vektorer.
Nu förstår jag varför Institute of Vector heter?
Hinton skapar ett fält av förvrängning av verkligheten, du är inledningsvis ges en känsla av tillförsikt och entusiasm, förtroende i det faktum att för vektorer, ingenting är omöjligt. I slutet, de har redan skapat självstyrande bilar att upptäcka cancer datorer, instant översättare av det talade språket.
Och bara när du lämnar rummet, kommer du ihåg att dessa system av “deep learning” är fortfarande ganska dum, trots deras demonstrativa power i tanken. Den dator som ser en hel del munkar på bordet och automatiskt loggar ut det som “ett gäng munkar som ligger på bordet” verka för att förstå världen, men när samma program ser en tjej som borstar sina tänder och säger att det är “pojke med ett baseball bat”, inser du hur svårfångade denna förståelse, om det någonsin är.
Ett neuralt nätverk är bara en tanklös och vaga identifierare bilder, och hur bra det kan vara sådana identifierare bilder — på grund av sin sträva efter att integrera i alla programvaror — de i bästa fall utgör en begränsad typ av intelligens som är lätt att fuska. Djupt neurala nätverk som känner igen bilden, kan vara helt förvirrad om du ändrar en pixel, eller lägga till visuella brus, omärklig för människor. Nästan lika ofta som vi hittar nya sätt att använda djupt lärande, ofta vi stöter på dess begränsningar. Självstyrande bilar får inte köra på villkor som inte har sett förut. Maskiner kan inte komma med förslag som kräver sunt förnuft och förståelse för hur världen fungerar.

Djupt lärande i en känsla härmar vad det är som händer i den mänskliga hjärnan, men ytligt — som kan förklara varför hans intelligens är så ytlig ibland. Backprop var inte identifieras i processen för att doppa i hjärnan försök att dechiffrera själva idén; det växte ut av modeller av djur lära sig genom trial-and-error i en gammaldags experiment. Och de flesta av de viktiga steg som har gjorts sedan starten, inte innehåller något nytt i ämnet för neurobiologi, det var en teknisk förbättring, välförtjänt år av arbete, matematiker och ingenjörer. Vad vet vi om intelligens, ingenting jämfört med vad vi inte vet ännu.
David Duvant, biträdande Professor vid samma Institution, och Hinton, University of Toronto, menar att djupt lärande tycks engineering introduktion till fysik. “Någon skrev att arbeta och sade: “jag gjorde denna bro, och han står!”. En annan skriver: “jag gjorde denna bro och det kollapsade, men jag lade till ett stöd, och det är värt det.” Och de go crazy på stöden. Någon lägger arch och alla, arch är cool! Med fysik så kan du faktiskt förstår vad som fungerar och varför. Vi har bara nyligen börjat gå till åtminstone en viss förståelse av artificiell intelligens”.
Och Professor Hinton säger: “de flesta konferenser tala om införandet av små förändringar istället för att behöva tänka och undrar, “Varför det vi gör nu inte fungerar? Vad är anledningen? Låt oss fokusera på det.”
Utsikten från utsidan är svårt att producera, när allt du ser är en kampanj för en befordran. Men de senaste framstegen inom AI, i mindre utsträckning, var en vetenskap och mer av teknik. Även om vi bättre förstår vilka förändringar som kommer att förbättra systemet för djupt lärande som vi vagt föreställa sig hur dessa system fungerar och om de någonsin kommer att träffa något så kraftfullt som det mänskliga sinnet.
Det är viktigt att förstå, har vi kunnat få allt du kan från backprop. Om Ja, sedan räknar vi med en platå i utvecklingen av artificiell intelligens.
Tålamod
Om du vill se nästa genombrott, en slags grund för en mycket mer flexibel intelligens, bör du, i teorin, hänvisa till studier, i likhet med studien av backprop i 80 år: när smarta människor ger upp på grund av att deras idéer inte fungerar ännu.
För några månader sedan besökte jag Center för Sinnen, Hjärnor och Maskiner, mångsidig anläggning, som ligger vid MIT, för att se hur min vän Mattias Dechter försvarar sin avhandling om kognitionsvetenskaplig. Innan föreställningen, hans fru Amy, hans hund ruby och hans dotter Suzanne har stöttat honom och önskade honom lycka till.
Den Eyal började sitt tal med en fascinerande fråga: hur är det att Suzanne, som är bara två år, lärt sig att tala, att spela, att följa historier? I den mänskliga hjärnan så att den gör det möjligt för honom att studera? Lära sig om datorn någonsin kommer att lära sig så snabbt och smidigt?
Vi förstå nya fenomen, i form av saker vi redan förstår. Vi bryter domän i bitar och studera bitar. Den Eyal är matematiker och programmerare, han tycker om uppgiften — till exempel göra en sufflé — hur komplexa datorprogram. Men du behöver inte lära dig att göra en souffle genom att memorera de hundratals små instruktioner som “sväng till armbågen 30 grader, sedan titta på bänkskivan, för att sedan dra ditt finger, sedan…”. Om du skulle göra det i varje nytt fall, utbildning skulle vara oacceptabel och skulle du ha stannat i utvecklingen. I stället ser vi att programmet åtgärder på högsta nivå som “piska äggvitorna”, som i sig består av underprogram som “sönder äggen och separera vitorna från gulorna”.
Datorer inte och därför ser dumma ut. Att djupt lärande erkänt hot dog, du måste mata henne 40 miljoner bilder av heta hundar. Bandet Suzanne lärt sig av hot dog, bara visa henne hot dog. Och långt innan att det kommer att ha en förståelse av språket, som går mycket djupare erkännande av förekomsten av enskilda ord tillsammans. Till skillnad från den dator i hennes huvud, en idé om hur världen fungerar. “Det förvånar mig att folk är rädda för att datorer kommer att ta deras jobb, säger Eyal. “Datorer kan ersätta advokater, inte på grund av att advokater är att göra något komplicerat. Men eftersom advokater är att lyssna och prata med människor. I denna mening är vi mycket långt bort från allt”.
Verklig intelligens kommer inte tveka, om du ändra något krav på att den lösningen. Och nyckeln avhandling av Eyal var ett bevis på att, i princip, hur man kan göra en dator som kör alltså: levande gälla alla som han redan känner till nya utmaningar, att snabbt ta tag i farten, för att bli en expert inom ett helt nytt område.
I själva verket är detta förfarande, som han kallar algoritmen “forskning-komprimering”. Det ger datorn en funktion av programmeraren att samla ett bibliotek med återanvändbara modulära komponenter som gör att du kan skapa mer komplexa program. Utan att veta något om nya domän som datorn försöker att strukturera kunskap om honom, helt enkelt studera hans befästa och upptäckte då att studera som ett barn.
Hans Rådgivare, Joshua Tenenbaum, en av de mest citerade forskare inom AI. Namnet på Tenenbaum dyka upp i hälften av de samtal jag har haft med andra forskare. Några av nyckelpersonerna i DeepMind — team AlphaGo, som slog världens legendariska mästare på spelet gå i 2016 — han arbetade under honom. Han är inblandad i en start som försöker ge självstyrande bilar, intuitiv förståelse av grundläggande fysik och avsikter hos andra förare att bättre kunna förutse de som förekommer i situationer som inte tidigare har haft.
Avhandlingen av Eyal har ännu inte tillämpats i praktiken, även i program infördes inte. “Problem på Mattias, en mycket, mycket svårt, säger Tenenbaum. “Vi måste få igenom en hel del generationer.”
När vi satte oss ner för att dricka en Kopp kaffe, Tenenbaum sade att utforskar historien om backprop för inspiration. I decennier, backprop var en manifestation av den svala matematik, för det mesta klarar av någonting. Så snart som datorerna blev snabbare och hårdare, allt förändrades. Han hoppades att något liknande kommer att hända med hans egna verk och verk av hans studenter, men “det kan ta ytterligare ett par decennier.”
För Hinton, han är övertygad om att övervinna de begränsningar av AI i samband med skapandet av en “bro mellan datavetenskap och biologi”. Backprop, från denna synpunkt, var en triumf för biologiskt inspirerade design, idén kom ursprungligen inte från teknik och från psykologi. Så nu Hinton försöker upprepa detta trick.
Idag neurala nätverk består av en stor platt lager, men i människans neocortex, dessa neuroner är ordnade inte bara horisontellt utan även vertikalt, i kolumner. Hinton vet varför vi behöver en sådan kolumner i en syn, till exempel, de gör det möjligt att känna igen objekt, även om du ändrar synvinkel. Så han skapar en konstgjord version — och kallar dem “kapslar” för att testa denna teori. Men det fungerar inte: kapsel är inte särskilt mycket bättre av dess nätverk. Men för 30 år sedan bactrobam var den samma.
“Det borde göra det”, säger han om teorin av kapslar, skrattar åt sina egna övermod. “Och vad fungerar inte ännu, detta är bara en tillfällig irritation.”
Material Medium.com
Artificiell intelligens Geoffrey Hinton: far till “djupt lärande”
Ilya Hel